Artifacts In Pipelines
Much of the behavior described here depends on looking up execution history in Redis. Deleting recent executions from Redis can cause unexpected behavior.
Now that you have an idea of what an artifact is in Spinnaker, you need to understand how it’s used within pipelines.
Spinnaker uses an “expected artifact” to enable a stage to bind an artifact from another pipeline execution, stage output, or running environment.
Expected artifacts
An “expected artifact” is a specification of what properties (found in the URI decoration) against which to match when searching for the desired artifact, plus optional fallback behavior.
Expected artifacts exist for two reasons:
- To declare what artifacts need to be present at a certain point during execution
- To provide easy ways to reference those artifacts
An expected artifact consists of an artifact to match (by name, type, etc…) plus, optionally, what to do if no artifact is matched. When an artifact is matched, we say it’s bound to that expected artifact.
The matching behavior is as follows: The artifact to match declared by the expected artifact has the same format as a regular artifact; however, its values are interpreted as regular expressions to match the corresponding values in the incoming artifact:
- Normal strings must match exactly for the artifact to match because Spinnaker
effectively treats them as regular expressions. For example, Spinnaker
interprets
inputstringas^inputstring$. - Explicit regular expressions are also valid. For example, Spinnaker
matches
.*inputstring.*to any string including the substringinputstring.
| Match Artifact | Incoming Artifact | Matches? |
|---|---|---|
{"type": "docker/image"} |
{"type": "docker/image", "reference: "gcr.io/image"} |
✔ |
{"type": "docker/image"} |
{"type": "gce/image", "reference: "www.googleapis.com/compute/v1/projects..."} |
✘ |
{"type": "docker/image", "version": "v1"} |
{"type": "docker/image", "reference: "gcr.io/image:test", "version": "v1"} |
✔ |
{"type": "docker/image", "version": "v1"} |
{"type": "docker/image", "reference: "gcr.io/image:test", "version": "v1.2"} |
✘ |
{"type": "docker/image", "version": "v1\..*"} |
{"type": "docker/image", "reference: "gcr.io/image:v1.2", "version": "v1.2"} |
✔ |
{"type": "docker/image", "version": "v1\..*"} |
{"type": "docker/image", "reference: "gcr.io/image:test", "version": "test"} |
✘ |
If an expected artifact matches anything other than a single artifact (and no fallback behavior is defined), the execution fails. Therefore it’s always safe to say “use the artifact bound by this upstream expected artifact” because if no artifact was bound, the pipeline wouldn’t be running this downstream stage.
Triggers
In Pipeline Configuration, you can now declare which artifacts a pipeline expects to have present before the pipeline starts running.
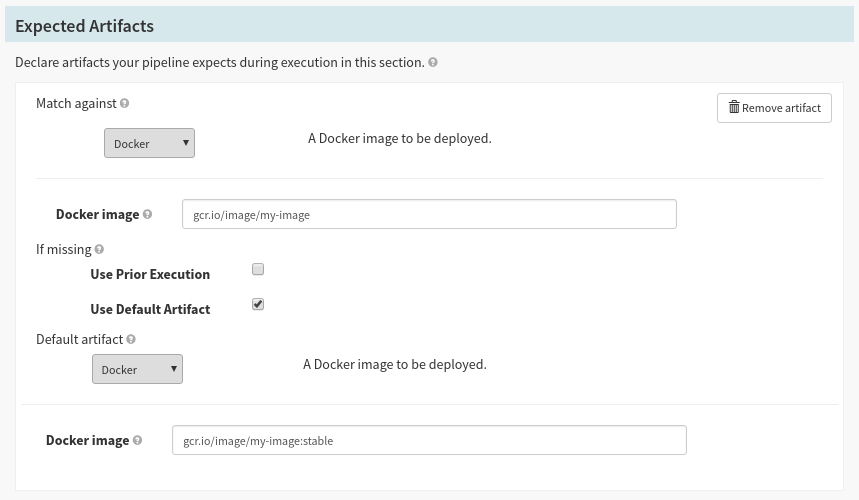
The UI provides short-hand for defining some types of artifacts—in this example a docker image. This is optional, but helps quickly define common types of artifacts.
You can define fallback behavior for when the artifact isn’t bound at the start of the Pipeline. The two options are evaluated in order:
-
Use Prior Execution
Use the artifact bound by the pipeline’s previous execution. This is useful in cases where multiple sources can trigger the pipeline, but each has incomplete information about what artifacts to supply.
-
Use Default Artifact
Specify exactly which artifact to bind.
Once you have declared which artifacts are expected by this pipeline, you can assign expected artifacts to individual triggers.
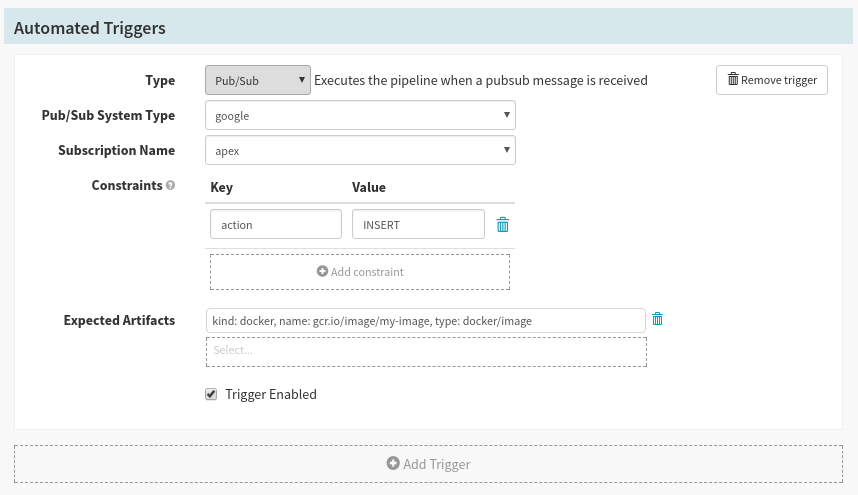
A pubsub subscription configured to listen to changes in one GCR registry. Since this registry can contain many repositories, we’ve assigned it an expected artifact to ensure only changes in one repository can run this pipeline.
When a trigger has one or more expected artifacts, it only runs when each expected artifact can bind to one of the artifacts in the trigger’s payload.
Artifacts in trigger payloads
Artifacts are supplied by payload as a list of artifacts in a top-level
artifacts key—the value is automatically injected into any triggered
pipeline’s execution context. However, it’s possible that you’re not the author
of the incoming message, and are instead depending on a third-party system to
provide an event to Spinnaker to trigger a pipeline. If this event contains
information such as “these images were created,” or “these files were
modified,” it’s useful to be able to extract artifacts from that payload.
For this reason, we allow you to supply Jinja templates that transform the incoming payload into a list of artifacts to be injected into your pipeline.
Take for example the notification format for GCR . While it captures the information we need, it’s not in the format we want. So, we can register the following Jinja template for our GCR subscription:
[
{
{% raw %}
{% set split = digest.split("@") %}
"reference": "{{ digest }}",
"name": "{{ split[0] }}",
"version": "{{ split[1] }}",
"type": "docker/image"
{% endraw %}
}
]
Find artifact from execution
To allow you to promote artifacts between executions, you can make use of the “Find Artifact from Execution” stage. All that’s required is the pipeline ID whose execution history to search, and an expected artifact to bind.

A common use case would be to “promote” the image deployed to staging to a pipeline that’s deploying to production.
Passing artifacts between pipelines
Artifacts can be passed between pipelines. If a pipeline triggers the execution of a second pipeline, this second pipeline will have access to any artifacts that were available to the first pipeline; this includes both artifacts in the first pipeline’s trigger as well as artifacts emitted by the first pipeline.
Two concrete cases where artifacts can be passed are as follows:
-
Pipeline triggered by the completion of another pipeline
To set up this configuration, go to the Configuration screen for a pipeline (Pipeline B) and add an automated trigger of type Pipeline pointing to another pipeline (Pipeline A). Whenever Pipeline A completes, it will trigger a run of Pipeline B, and Pipeline B will have access to all artifacts from Pipeline A.
-
Pipeline that is a stage of a parent pipeline
To set up this configuration, go to the parent pipeline (Pipeline A), choose Add Stage, and add a stage of type Pipeline pointing to another pipeline (Pipeline B). In this case, Pipeline B will have access to any artifacts from Pipeline A that are upstream from where it was triggered.
Stages that produce artifacts
Stages can be configured to ‘Produce’ artifacts if they expose the following Stage configuration:
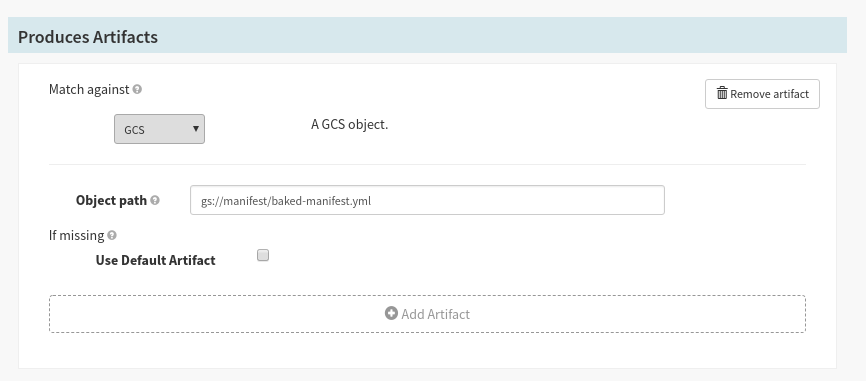
If you are configuring your stages using JSON, the expected artifacts are
placed in a top-level expectedArtifacts: [] list.
There are two ways to use this:
-
To bind artifacts injected into the stage context
If your stage emits artifacts (such as a “Deploy (Manifest)” stage) into the pipeline context, you can match against these artifacts for downstream stages to consume.
-
To artificially inject artifacts into the stage context
If you are running a stage that does not natively emit artifacts (such as the “Run Job” stage), you can use the default artifact, which always binds to the expected artifact, to be injected into the pipeline each time it is run. Keep in mind: If the matching artifact is empty, it will bind any artifact, and your default artifact will not be used.
A visual explanation
To help explain how artifacts & expected artifacts work, let’s walk through a demo pipeline. To begin, here is the key:

Say we’ve configured the following pipeline:

The pipeline declares that it expects an artifact matching 1 (perhaps a docker image) when the pipeline starts. This is done in the pipeline configuration tab. It also expects an artifact matching 2 in pipeline stage B (perhaps a “Find Artifact from Execution” stage).
The pipeline is triggered by some source (maybe a Webhook) supplying two artifacts:

Artifact 1 is bound, but both incoming artifacts are placed into the trigger, so any downstream stages (in this case all of them) can consume them. The advantage of the expected artifact is that stages can explicitly reference whatever artifact is bound downstream, rather than have to check for existance of the artifact at runtime.

It’s important to keep in mind that artifact 1 was bound when the pipeline started. If we reference the expected artifact downstream (such as in the “Deploy Manifest”) stage shown below, it is using the artifact that was bound when the pipeline first executed, not when the stage shown runs.
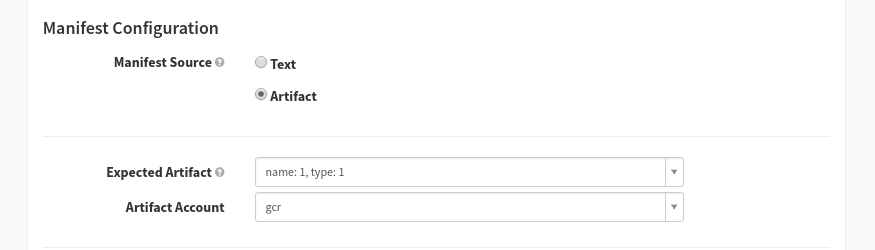
When stage B starts executing, it needs to bind expected artifact 2. If, for example, it was a “Find Artifact from Execution” stage, it would do so by looking up the artifact from a another pipeline’s execution, and binding it here.

If stages C or D needed to reference an upstream artifact, they would have different artifacts accessible to them, since they have different upstream stages. For examples, stage D does not have access to artifact 2.
